Materia: #organizacion_del_computador_II
Tags: Arquitectura Intel 64
Paralelismo de instrucciones
Historicamente cada ejecucación toma 5 pasos (en general), donde cada uno demora un clock. El circuito seria el siguiente:
flowchart TD busqIn[Búsqueda de\n instrucción] decod[Decodificación\n de instrucción] busqOp[Búsqueda de \n operandos] ejec[Ejecución] res[Resultado] busqIn --> decod decod --> busqOp busqOp --> ejec ejec --> res res --> busqIn
Estas etapas son consideradas las mínimas para la ejecución de cualquier instrucción. Es bastante inaceptable que cada instrucción nos demore multiples ciclos de clock, por lo que se desarrollo una forma para que cada instrucción se ejecutase en un unico ciclo.
Esta idea se le conoce como paralelismo de instrucciones (ILP, por sus siglas en inglés), y consiste en ejecutar estas etapas al mismo tiempo, pero sobre instrucciones distintas. Esto se representa mejor en el siguiente grafico:
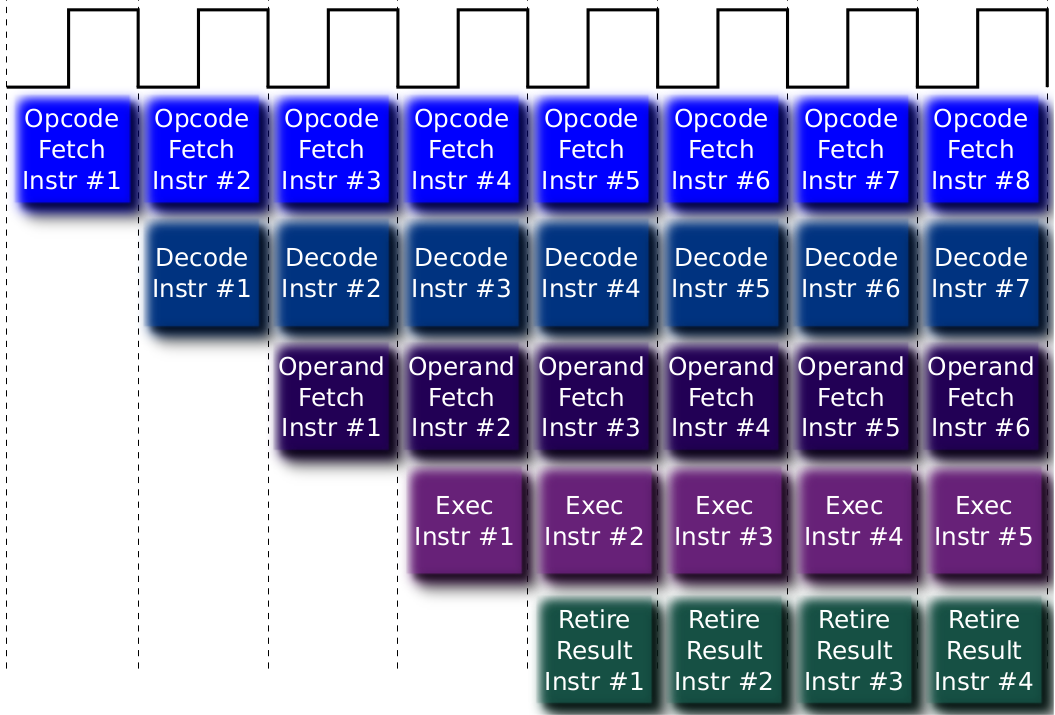
Si bien al principio hay
En base a estas conclusiones, podemos pensar que siempre y cuando las microinstrucciones ocupen un clock de tiempo, entonces vale la pena trabajar bajo este modelo de ejecución. Es decir, necesitamos mas etapas y mas simples. Un ejemplo de una expansion de etapas puede ser:
graph TD insAddressCalc[Calculo de\n dirección de\n instrucción] insFetch[Fetch de\n instrucción] insOpDec[Decodificado\n de operación] opAddressCalc[Calculo de\n dirección de\n operandos] opFetch[Fetch de\n operandos] dataOp[Operación\n de data] opAddressCalc2[Calculo de\n dirección de\n operandos] opStore[Guardado\n de datos] insAddressCalc --> insFetch insFetch --> insOpDec insOpDec --> opAddressCalc opAddressCalc --> opFetch opFetch --> opAddressCalc opFetch --> dataOp dataOp --> opAddressCalc2 opAddressCalc2 --> opStore opStore --> opAddressCalc2 opStore --> insAddressCalc
Como veran, es bastante mas engorroso pero para el modelo ILP es mucho mas optimo. Aumentar la cantidad de etapas nos es practico ya que, en promedio, podemos afirmar que:
Donde
El modelo ILP no reduce el tiempo de cada instrucción individual, si no que incrementa la cantidad de instrucciones completadas por unidad de tiempo. Esto lo que provoca es que se pueden generar cuellos de botella. Por ejemplo, si una instrucción requiere como operando el resultado de la operación anterior, entonces deberia atrasar a todas las demas para que cuando sea ejecutada tenga todos los operandos disponibles. Otro ejemplo, son los accesos a memoria, que directamente retrasan toda la operacion en general. Por ultimo, lo mas dificil de manejar serian los saltos en el codigo, ya que hay instrucciones que al momento del salto se van a encontrar fetcheadas o en proceso de estarlo.
Por ejemplo, en el siguiente codigo:
mov r8, 0x01
mov r9, 0x02
add r8, r9
podemos ver como la tercera linea depende de la ejecución y terminación de las dos anteriores. No puede sumar el registro r8 con el r9 si todavia no guardo los valores correctos ahi.
Los accesos a memoria y las operaciones combinadas tienen una solucion relativamente sencilla, que consiste en atrasar el ciclo paralelo, de modo que el resultado de una operación ingrese directamente como entrada de la siguiente, por hardware, en un solo clock. A este concepto se lo conoce como forwarding. Esto es relativamente sencillo de hacer, y simplemente se pierden
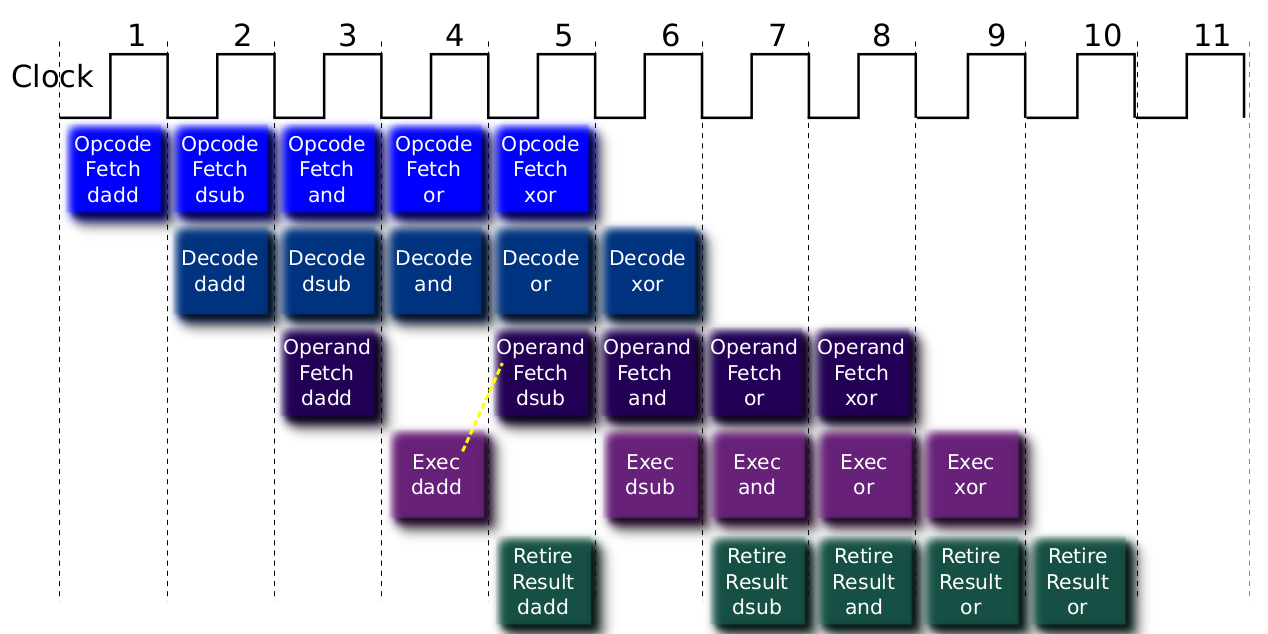
Ahora lo unico que queda por resolver son los saltos, que es la situación donde mas performance puede perderse. Pensemos un segundo en la situacion de las instrucciones paralelas: a la hora de ejecutar el salto, vamos a tener unas cuantas instrucciones que ya fueron fetcheadas, decodificadas o incluso que tienen sus operandos calculados, y van a tener que ser descartadas, ya que al hacer el salto las instrucciones a ejecutar van a ser diferentes.
Predicción de saltos
Si un salto es obligatorio, no hay problema, ya que esto se puede deducir en la operación de decodificado, por lo que no se perderian muchos clocks. El problema real aparece cuando tenemos un salto condicional, ya que dependiendo de si dicho salto se efectua o no, se perderian clocks en instrucciones que no se ejecutarian en ese momento. Para resolver esto se diseño el branch prediction buffer (o buffer de predicción de saltos), que consiste en utilizar los bits menos significativos de las direcciones en el Program Counter, que indican el resultado reciente del salto (taken o non-taken).
Es decir, los dos bits menos significativos de cada direccion de memoria del programa, nos van a indicar si el salto potencialmente puede ser tomado o no, bajo la siguiente logica. Si tenemos dos bits, podemos tener 4 posibles estados:
graph TD spT((11\n Predicción fuerte\n Taken)) wpT((10\n Predicción débil\n Taken)) spN((00\n Predicción fuerte\n Non-taken)) wpN((01\n Predicción débil\n Non-taken)) spT -->|Taken| spT spN -->|Non-taken| spN spT -->|Non-taken| wpT wpT -->|Taken| spT spN -->|Taken| wpN wpN -->|Non-taken| spN wpT -->|Non-taken| spN wpN -->|Taken| spT